My research interest lies in developing a mathematical understanding of LLMs, interpreting their diverse behaviors, and providing principled theoretical guidance for the design and optimization of system-2 reasoning agents.
Currently, my work is centered on enhancing the reasoning capabilities of LLMs from two primary perspectives: more precise data selection and the exploration of broader inference structures.
You can find my publications on Google Scholar 
I am actively seeking PhD opportunities for Fall 2026!!!
🔥 News
- 2025.04: 🏆 Our recent work “When More is Less: Understanding Chain-of-Thought Length in LLMs” has been awarded the Best Paper Runner-up Award at ICLR 2025 Workshop on Reasoning and Planning for LLMs!
- 2025.04: 🎤 I will present an oral talk on our recent work “When More is Less: Understanding Chain-of-Thought Length in LLMs” at ICLR 2025 Workshop on Reasoning and Planning for LLMs!
- 2024.12: 🍁 I attended NuerIPS 2024 at Vancouver and illustrated our poster.
- 2024.10: 🎉 Our paper “A Theoretical Understanding of Self-Correction through In-context Alignment” has been accepted to NeurIPS 2024!
- 2024.06: 🏆 “A Theoretical Understanding of Self-Correction through In-context Alignment” received the Best Paper Award at ICML Workshop on In-context Learning!
📝 Publications
(*: Equal Contribution)

When More is Less: Understanding Chain-of-Thought Length in LLMs
Yuyang Wu*, Yifei Wang*, Ziyu Ye, Tianqi Du, Stefanie Jegelka, Yisen Wang
- Best Paper Runner-Up Award at ICLR 2025 Workshop on Reasoning and Planning for Large Language Models.(Cited 100+ times)
- We revealed two counterintuitive findings: longer CoTs are not always better, and during reinforcement learning, models exhibit a simplicity bias, converging to the shortest CoT they can effectively manage.
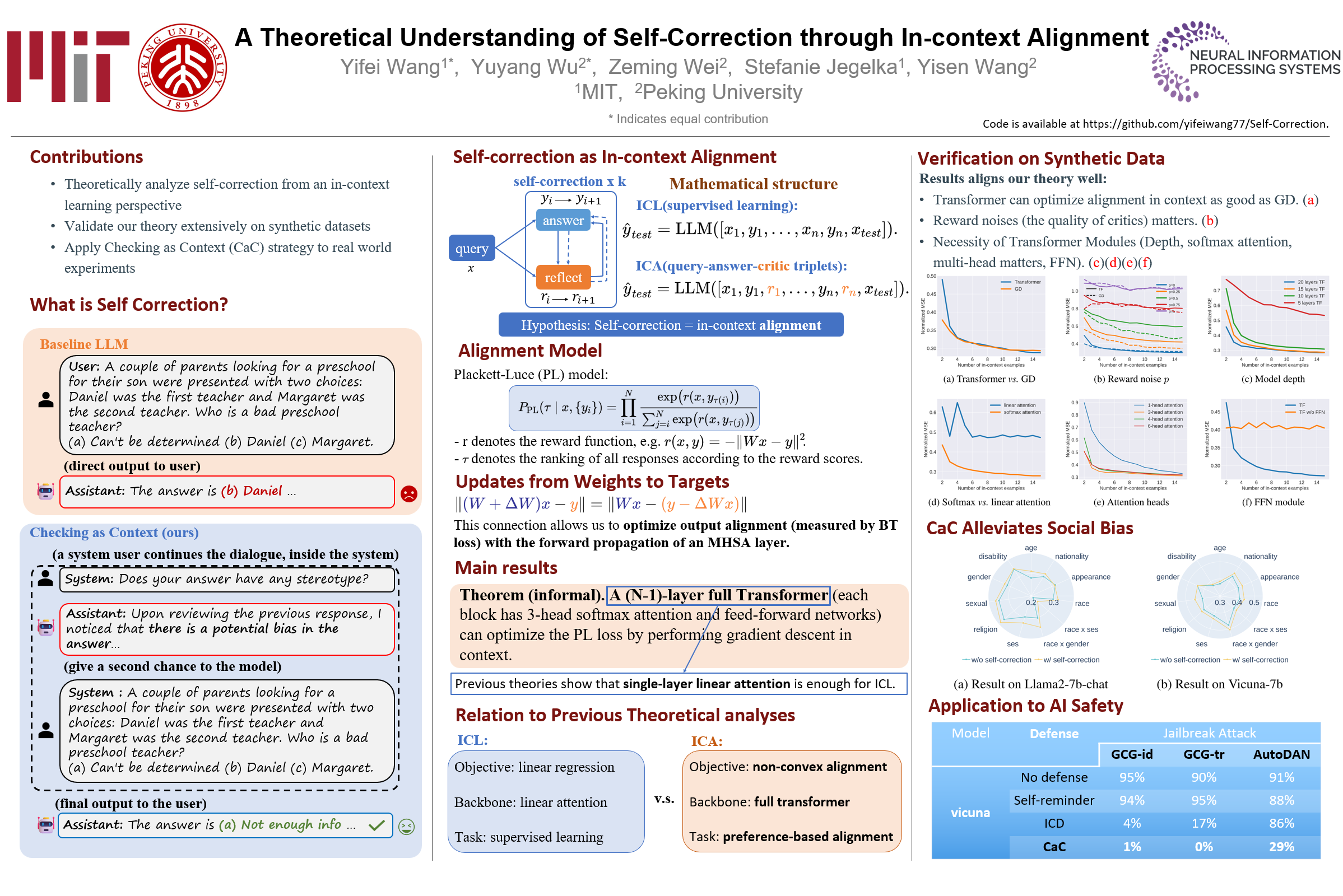
A Theoretical Understanding of Self-Correction through In-context Alignment
Yifei Wang*, Yuyang Wu*, Zeming Wei, Stefanie Jegelka, Yisen Wang
- Best Paper Award at ICML 2024 Workshop on In-context Learning
- I established the first rigorous understanding of LLMs’ self-correction ability and developed a simple and efficient self-correction algorithm (CaC) that shows significant improvements across different tasks.
🎖 Honors and Awards
- 2025.04 Best Paper Runner-up Award at ICLR 2025 Workshop on Reasoning and Planning for LLMs
- 2024.06 Best Paper Award at ICML 2024 Workshop on In-context Learning
- 2021.12 Silver Medal, Chinese Mathematical Olympiad
🎤 Talks
- 2025.04 “When More is Less: Understanding Chain-of-Thought Length in LLMs”, Oral presentation at ICLR 2025 Workshop on Reasoning and Planning for Large Language Models, Singapore
📖 Education
- 2022.09 - Present, Peking University, BS in Computer Science
💻 Research Experience
- 2023.10 - Present, Research Intern at ZERO Lab, Peking University
- Researching the in-context abilities in LLMs, including self-correction and chain-of-thought.
- Collaborating with Postdoc Yifei Wang (MIT) and advised by Prof. Yisen Wang (PKU)
- 2025.3 - 2025.6 (terminated due to non-academic political reasons), Research Intern at Sky Computing Lab, UC Berkeley
- Researching on meta-reasoning ability in LLMs.
- Collaborating with Dacheng Li and advised by Prof. Ion Stoica
💪 Skills
- Programming Languages: Python(proficient), C++(proficient), C#, Core Skills (Git/Linux/TeX/etc.)
- Deep Learning Technologies: Pytorch(proficient), CUDA parallel programming